체결 데이터(틱데이터)를 사용할 때, 데이터가 지나치게 raw해서 생기는 난감한 부분들이 많습니다. 이를 해결하기 위해 “분봉”이나 “일봉”처럼, 일정한 시간을 기준으로 체결내역을 grouping하는 전처리 방법이 가장 많이 사용되는 것 같습니다. 이러한 방법의 장단점은 무엇일까요? 혹시 다른 방법은 없을까요? 어떻게 구현을 해야 할까요?
Marcos Lopez de Prado의 저서 Advances in Financial Machine Learning에 위 질문들에 대한 답변이 정리가 잘 되어있습니다. 이번 포스팅은 해당 서적의 “2.3 Financial Data Structures: Bars” 챕터를 공부하며 이해한 내용을 정리한 내용입니다. 워낙 유명한 저서인지라, 책의 내용에 대한 구현을 정리해놓은 github repo도 있습니다. 다만, 모듈화를 위해 로직이 흩어져있어서 이해하기가 쉽지 않아, Python pandas를 사용하여 직접 구현을 해보았습니다.
포스팅의 내용 혹은 코드에 개선이 필요한 경우, 피드백을 주시면 감사하겠습니다. :)
시작하기에 앞서, 체결시각($t$)과 체결가격($p_t$, price), 체결량($v_t$, volume)으로 이루어진 틱 데이터가 필요합니다. 특별한 비용 없이도 증권사나 암호화폐 거래소 API를 사용하여 가져올 수 있습니다. 다음은 이베스트증권 API를 통해 받은 2020년 3월 25일 삼성전자(005930)의 틱데이터입니다. 추후 계산 편의를 위하여 거래대금($a_t$, value)을 $p_t\cdot v_t$로 미리 계산하였고, 인덱스로 사용된 체결시각을 오름차순으로 정렬했습니다.
우리의 목표는 위 데이터를 이해하기 쉽고 사용하기 편한 (일종의) 테이블 형태로 변환하는 것입니다. 이러한 테이블의 행(row)을 “bar” 라고 부릅니다. 이번 포스팅에서는 bar를 추출하는 다양한 방법들을 소개합니다.
1. Standard Bars
1.1. Time bars
Definition
일정한 시간 간격으로 bar를 추출하는 방법으로, 흔히 접하는 “분봉”, “일봉” 등이 이에 속합니다. 시간 흐름에 따른 가격과 수급 현황을 확인할 수 있어서 가장 직관적인 데이터 형태이지만, 몇 가지 문제점들이 있습니다.
시장이 일정한 시간 단위로 정보를 처리하지 않습니다. 일정한 시간을 기준으로 데이터를 추출할 경우, 거래가 활발하지 않은 시기에는 데이터가 oversample 되고, 거래가 활발한 시기에는 undersample 되는 문제가 생깁니다.
일정한 시간으로 추출된 시계열 데이터의 통계 특성(i.e. serial correlation, heteroscedasticity, non-normality of returns)이 좋지 않은 경우가 많습니다.
이러한 문제들은 (앞으로 소개 될) 거래 내역을 기반으로 데이터를 추출하는 방법을 통해 해결할 수 있습니다.
Implementation
시계열 DataFrame(DataFrame with datetime-like index)에는 주어진 규칙에 따라 데이터를 정렬 할 수 있는 resample method가 있습니다. 이를 Resampler.ohlc와 같이 사용하면, 틱 데이터를 쉽게 timebar로 변환할 수 있습니다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14
deftimebar(tick, rule): resample = tick.resample(rule) bars = resample['price'].ohlc() # 거래가 일어나지 않은 시간의 NaN 처리 bars['close'] = bars['close'].fillna(method='ffill') bars['open'] = bars['open'].fillna(bars['close']) bars['high'] = bars['high'].fillna(bars['close']) bars['low'] = bars['low'].fillna(bars['close']) bars[['volume', 'value']] = resample[['volume', 'value']].sum() return bars
>>> timebar(samsung, '30s') t open high low close volume value 2020-03-25 08:30:0046950.046950.046950.046950.01667793700 2020-03-25 08:30:3046950.046950.046950.046950.000 2020-03-25 08:31:0046950.046950.046950.046950.0432018850 2020-03-25 08:31:3046950.046950.046950.046950.0311455450 2020-03-25 08:32:0046950.046950.046950.046950.0753521250 ... ... ... ... ... ... ... 2020-03-2517:58:0049000.049000.049000.049000.000 2020-03-2517:58:3049000.049000.049000.049000.000 2020-03-2517:59:0049000.049000.049000.049000.000 2020-03-2517:59:3049000.049000.049000.049000.000 2020-03-2518:00:0049050.049050.049050.049050.0432682122295400
[1141 rows x 6 columns]
>>> timebar(samsung, '1H') t open high low close volume value 2020-03-25 08:00:004695046950469504695090842630600 2020-03-25 09:00:004890049600475504805019104046930657231400 2020-03-2510:00:00480504870047900483506251831302241758300 2020-03-2511:00:00483504845047800483004902528235849172200 2020-03-2512:00:00482504845048000481502985362143843200950 2020-03-2513:00:00481004820047150481006703650320201734850 2020-03-2514:00:00481004890047550488007213952347588903150 2020-03-2515:00:00488504890048450486505089598247668090050 2020-03-2516:00:0048600487004855048700881254285782150 2020-03-2517:00:00488004900048800490001723268422908900 2020-03-2518:00:0049050490504905049050432682122295400
1.2. Tick bars
Definition
일정한 수의 체결이 발생하였을 때마다 bar를 추출하는 방법입니다. 체결이 많이 일어나는 시점에는 더 많은 bar가 추출되기 때문에, 시장으로 들어오는 정보의 속도를 time bar보다 잘 반영합니다. 또한, tick bar로 계산되는 수익률($r_i$)이 iid 정규분포에 더 가깝다는 연구도 있습니다. (Ane & Geman, 2000)
하지만, 다음과 같은 점들이 문제가 될 수 있습니다.
다수의 주문들이 한번에 체결되는 경우 outlier가 발생할 수 있습니다. 예를 들어, 장 마감 전 동시호가 시간(15:20~15:30)에는 주문이 체결되지 않고 누적되다가, 15:30분에 주문들이 한번에 체결되며 하나의 틱으로 처리가 됩니다. 하나의 틱이 수많은 체결을 포함하고 있는 셈입니다.
반대로, 하나의 주문이 여러번에 걸쳐 체결이 되는 경우도 문제가 됩니다. (a.k.a. “order fragmentation”) 정상적인 주문에 의한 다수의 체결인 경우에는 상관 없을 수 있지만, 트레이딩 봇에 의한 경우나 (운용/개발 편의를 위해) 체결 엔진에 의한 경우에는 데이터에 왜곡이 생길 우려가 있습니다.
Implementation
Tick bar는 time bar와 비슷한 방법으로 구현이 가능합니다. 이전과는 다르게, 체결 시각을 기준으로 데이터를 resampling 하는 것이 아니므로, 새로운 인덱스(window_number)를 추가한 뒤 groupby() method를 통해 데이터를 묶어주었습니다.
>>> tickbar(samsung, 10) t open high low close volume value 2020-03-25 08:30:02 4695046950469504695031514789250 2020-03-25 08:32:374695046950469504695033815869100 2020-03-25 08:35:514695046950469504695025511972250 2020-03-25 09:00:26489004895048900489003150154048850 2020-03-25 09:00:26489004895048900489509649471903050 ... ... ... ... ... ... ... 2020-03-2515:59:114865048650486504865063030649500 2020-03-2515:59:26486504865048650486502275110678750 2020-03-2515:59:404865048650486004860015808768327150 2020-03-2516:20:234860049000485504900024581011997138450 2020-03-2518:00:1549050490504905049050432682122295400
[22709 rows x 6 columns]
1.3. Volume bars
Definition
일정한 수준의 거래량이 발생할 때마다 bar를 추출하는 방법입니다. 거래량을 기준으로 데이터를 추출하기 때문에, order fragmentation에 의해 데이터가 왜곡되는 tick bar의 문제점을 어느정도 해결할 수 있습니다. Tick bar로 계산되는 수익률보다 volume bar로 계산되는 수익률이 iid 정규분포에 더 가깝다는 연구도 있습니다. (Clark, 1973) 이뿐만 아니라, 가격과 거래량의 상호작용에 대한 시장 미시구조 이론들을 적용하기에도 용이합니다.
다만, “거래량 하나”의 가치가 시장의 여러 요인들에 의해 지속적으로 변한다는 점을 감안해야 합니다. 따라서 가격 변동이 큰 데이터(ex. 암호화폐)를 사용하여 volume bar를 추출 할 경우, 각 bar의 “가치” 차이가 클 수 있습니다. 가격의 변동 뿐만 아니라, 유통 주식수에 영향을 주는 이벤트(주식발행, 액면 병합/분할, 자사주 매입 등)도 단위 거래량의 가치를 변동시킬 수 있다는 점을 조심해야 합니다.
(Naive) Implementation
모든 bar가 (정확하게) 동일한 단위 거래량을 가지도록 volume bar를 추출하기 위해서는 iteration이 필요해 보입니다. (누적 거래량이 단위 거래량을 넘어가는 순간, 하나의 틱을 여러개로 나눠야 하는 로직이 필요할 것 같습니다.) 이 경우, numpy의 효율적인 퍼포먼스를 충분히 활용하기가 어렵습니다.
Tick bar를 계산하는 방법을 응용하면, volume bar를 approximate 할 수 있는 bar를 아래와 같이 계산할 수 있습니다. 단위 거래량이 커질수록, 아래의 방법으로 계산 된 bar는 volume bar와 유사해집니다.
>>> naive_volumebar(samsung, 500_000).head(10) t open high low close volume value 2020-03-25 08:30:02+09:004695046950469504695090842630600 2020-03-25 09:00:26+09:00489504895048500487502999031146769006600 2020-03-25 09:00:36+09:004880048850483504850049941524269779250 2020-03-25 09:01:07+09:004845048800484504875050046224323620400 2020-03-25 09:01:47+09:004875049000487004900048048823495366100 2020-03-25 09:02:32+09:004900049250490004925051783225422146200 2020-03-25 09:03:08+09:004925049500492004950050184424769576200 2020-03-25 09:03:55+09:004950049600494504950049885524702622450 2020-03-25 09:04:26+09:004950049600492504940050101124745938700 2020-03-25 09:05:46+09:004940049500493004935050014924708946850
거래가 상대적으로 적게 일어나는 종가매매 시간(08:30)과 시가단일가 주문이 한번에 체결되는 장 개시 시점(09:00)을 제외하면, 거래량이 50만주에 가깝게 bar들이 추출되었습니다. 참고로 500_000에서 underscore(_)는 가독성을 위하여 자릿수를 나누어 주는 역할을 하고, 실제 값은 500000과 동일합니다. (PEP-515)
1.4. Dollar bars
Definition
일정한 수준의 거래대금이 누적 될 때마다 bar를 추출하는 방법입니다. 실제 거래되는 현금의 양을 기준으로 데이터를 처리하기 때문에, volume bar에 비해 가격변동, 주식발행, 액면 병합/분할, 자사주 매입 등의 이벤트에 대해 robust하고, 단위 거래량의 가치 변화에 조금 더 consistent 합니다.
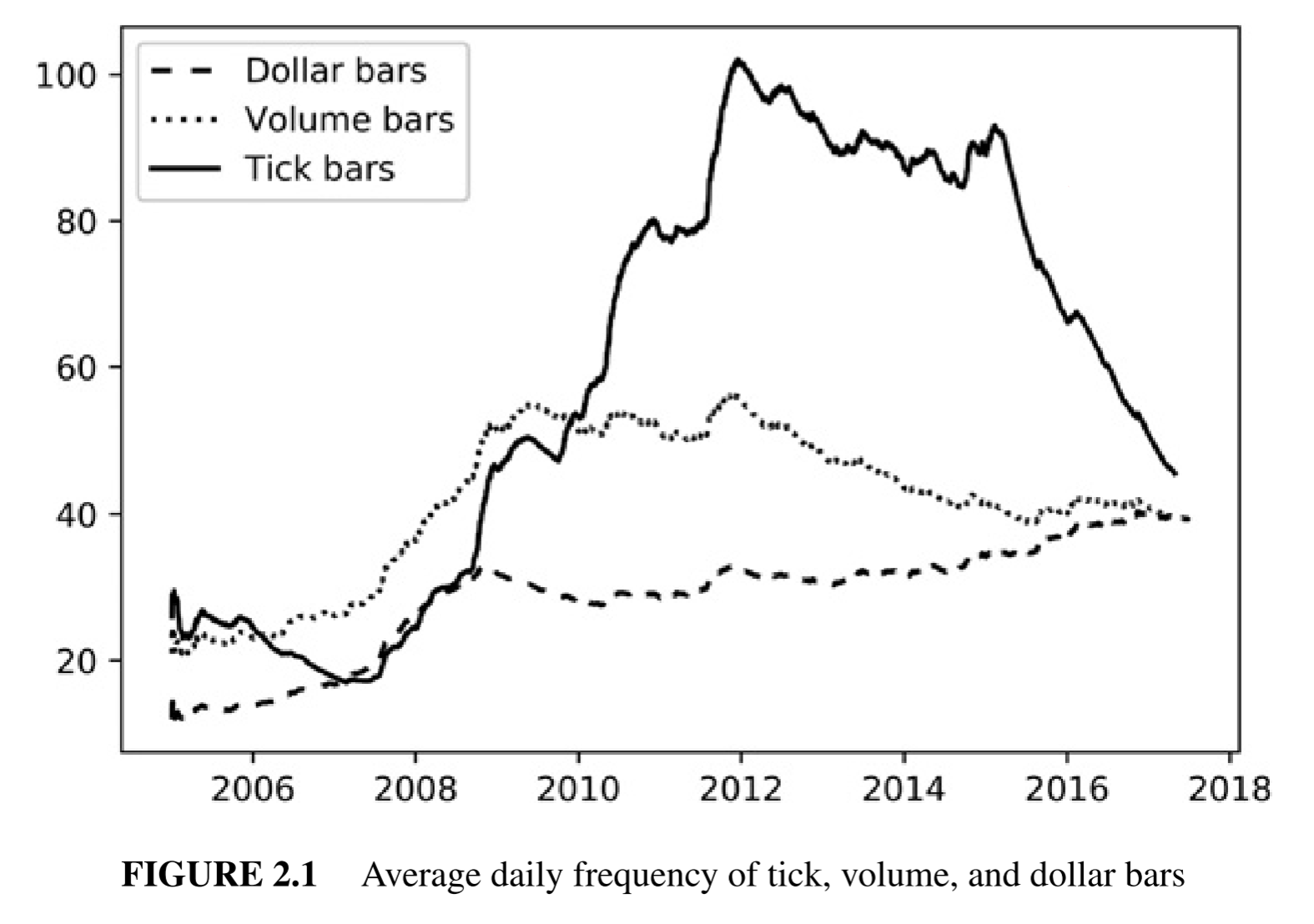
위 그림은 E-mini S&P 500 선물 틱 데이터를 tick bar, volume bar, dollar bar로 계산한 뒤, 하루에 발생하는 bar의 개수를 나타낸 그래프입니다.(Lopez de Prado, 2018) 다른 데이터에 비해서 dollar bar가 더 consistent하게 추출되는 경향을 볼 수 있습니다. 더 나아가서, 각 bar를 추출하는 단위 거래대금의 크기를 유동적으로 조절하여(ex. 유동시가총액에 비례하는 단위), 보다 더 consistent한 데이터를 얻을 수 있겠습니다.
(Naive) Implementation
거래량 또는 거래대금을 기준으로 bar를 추출한다는 점만 제외하면, dollar bar는 volume bar와 같은 로직을 가지고 있습니다. Volume bar의 구현을 참고하여 다음과 같이 구현할 수 있습니다.
>>> naive_dollarbar(samsung, 50_000_000_000).head(10) t open high low close volume value 2020-03-25 08:30:02+09:004695046950469504695090842630600 2020-03-25 09:00:26+09:00489504895048500488003058052149640289350 2020-03-25 09:00:40+09:0048500488504835048850102584949868417850 2020-03-25 09:01:58+09:0048850493504880049300102829050435367200 2020-03-25 09:03:21+09:0049300496004925049300101043149977830750 2020-03-25 09:04:58+09:004930049500492504935097207448001468250 2020-03-25 09:06:53+09:0049300493504875048800106096152033926150 2020-03-25 09:08:27+09:0048800491504865049100102303349984091500 2020-03-25 09:11:17+09:0049100492504880048850102025350014684300 2020-03-25 09:14:15+09:0048850488504835048400102882949976391950
Volume bar와 비슷한 이유로, 장 시작 직전과 직후를 제외하면, 각 bar의 거래대금이 50BnKRW에 가깝게 데이터가 처리되었습니다.
2. Information-Driven Bars
2.0. The tick rule
Definition
Information-driven bar는 시장에 새로운 정보가 유입되었을 때, 더 많은 bar를 추출하는 접근방법입니다. 시장에 새로운 정보가 유입이 되었다는 사실은 어떻게 알 수 있을까요?
시장미시구조론에서는 다음과 같은 흐름으로 논리가 전개됩니다. 시장에 새로운 정보가 유입이 되었을 경우, 해당 정보를 참고하여 시장에 참여하는 “informed trader”들이 생깁니다. 이로 인해 가격은 새로운 균형점으로 이동하려고 하고, 그 과정에서 매도/매수 세력이 불균형해집니다. 역으로 생각해보면, 이러한 불균형이 관찰이 된다면 시장에 새로운 정보가 반영되었다고 유추를 할 수 있습니다. 즉, 시장 외부 이벤트들을 (NLP 등을 이용하여) 직접 포착하는 것이 아니라, 이벤트가 시장에 녹아들 때 발생하는 시장의 현상을 포착하는 것입니다.
이를 위해서는, “매도/매수 세력의 불균형”을 수치화하여 활용해야 합니다. 한 가지 방법으로, 틱 데이터에 tick rule을 적용하여 signed tick ($b_t \in {-1, 1}$) 을 정의할 수 있습니다.
복잡해 보이는 식이지만, 의미는 간단합니다. 거래가 직전 거래보다 높은 가격에 체결됐을 경우 1, 낮은 가격에 체결됐을 경우 -1, 같은 가격에 체결됐을 경우 $b_{t-1}$ 값을 그대로 사용하는 방법입니다.
Signed tick은 trade’s agressor side를 수치화하기 위한 알고리즘입니다. 거래가 체결되는 형태는 크게 “지정가 매도주문 + 시장가 매수주문”이 매칭이 되는 경우와 “시장가 매도주문 + 지정가 매수주문”이 매칭이 되는 경우가 있습니다. 매도호가가 매수호가보다 크기 때문에, 전자의 체결가가 더 높습니다. 즉, 직전 거래와 비교하였을 때 체결가가 높다면, 이번 거래는 시장가 매수주문에 의해 체결되었을 가능성이 높은 셈입니다. (아래 Pitfall 항목에서 언급하겠지만, 항상 그렇지는 않습니다.) 이를 반영하여 signed tick을 다르게 설명하면, 시장가 매수주문에 의해 거래가 발생한 경우 $b_t=1$, 시장가 매도주문에 의해 거래가 거래가 발생한 경우에는 $b_t=-1$으로 정의하는 방법이라고 할 수 있습니다.
자산(혹은 계약)의 가격이 상승압력을 받게 되면 시장가 매수주문이 많이 발생하게 되고, $b_t=1$인 경우가 상대적으로 많이 관찰이 될 것입니다. 따라서, $b_t=1$인 경우가 어느 수준 이상 관찰될 때마다 bar를 추출하면, 시장에 유입되는 정보를 기준으로 bar를 추출할 수 있습니다. 반대의 경우($b_t=-1$)도 마찬가지 입니다.
Pitfall
호가가 변하는 경우, agressor side를 제대로 파악하지 못하는 문제가 생깁니다. 아래의 예시를 보겠습니다.
매도호가 11,000원, 매수호가 10,000원인 주식, 이전 체결가 10,000원 ($p_0=10000$)
$t=1$ 시점에서 시장가 매수주문 접수, 체결 ($p_1=11000$, $b_1=1$)
지정가 매도주문 10,900원으로 접수. 현재 매도호가 10,900원, 매수호가 10,000원
$t=2$ 시점에서 시장가 매수주문 접수, 체결 ($p_2=10900$, $b_2=-1 \because \Delta p_2<0$)
시장가 매수주문이 체결되었음에도, $b_2=-1$이 되는 문제가 발생합니다. 매수주문과 매도주문이 균형있게 체결되는 시장에서 위의 문제는 시간이 지나면서 해소가 될 수 있습니다. 하지만 유동성이 부족하거나 변동이 큰 종목의 경우에는 문제가 될 소지가 있으므로, 이에 대해 인지를 하고 있어야 합니다.
사용하는 API에 따라, signed tick 정보를 제공하는 경우도 있습니다. 예를 들어 코인원 API에서 제공하는 최근 체결 내역의 경우, 체결 시각과 체결가, 체결량과 함께 agressor side를 명시한 is_ask라는 데이터를 함께 제공합니다. 이 경우, 해당 데이터를 signed tick으로 활용하는 방법도 고려해볼 수 있겠습니다.
Signed tick을 계산하기 위해서 필요한 직전 거래의 체결가를 구하기 위해, pandas의 shift() method를 사용합니다. 체결가에 변동이 없는 경우, diff가 0이 되어 abs(diff)/diff 값이 np.nan으로 계산되도록 한 뒤, ffill() (forward fill)을 통해 이전 값을 사용하도록 합니다. 틱 데이터의 앞 부분에서는 signed_tick이 정의될 수 없으므로, 임의의 값 (initial_value=1.0)을 넣어줍니다.
Signed tick이 편향되었다는 판단은 다양한 방법으로 내릴 수 있습니다. 그 중 한 방법으로, signed tick을 누적하여 tick imbalance ($\theta_T$) 를 정의할 수 있습니다. $T$ 시점에서의 tick imbalance는 다음과 같이 정의됩니다.
여기서 $E_0[T]$는 현 시점에서 예상되는 다음 bar의 크기 (틱의 개수), $E_0[b_t]$은 $b_t$의 기대값입니다. $E_0[T]$와 $E_0[b_t]$ 값을 구하는 방법 중 하나는, 이전에 추출된 tick imbalance bar들의 $T$값과 $b_t$값에 exponentially weighted moving average를 적용하여 사용하는 방법이 있습니다.
마지막으로, tick imbalance의 크기가 예상 tick imbalance를 넘어가는 순간에 bar를 정의합니다.
Bar를 정의하는데 사용된 데이터($t \in [1,T^*]$)를 제외하고 위의 과정을 반복해주면, 전체 데이터에 대한 tick imbalance bar를 정의할 수 있습니다.
틱 데이터가 예상한 것 이상으로 불균형 할 때 $\theta_T$ 값은 커지고, 더 작은 $T$ 값으로도 $T^*$를 정의할 수 있습니다. 다르게 이야기하면, 정보의 비대칭으로 인하여 방향성이 있는 informed trading이 시장에 많이 존재 할 수록, TIB는 더 많이 생성됩니다. 따라서, TIB는 일종의 “동일한 양의 정보를 포함하는 데이터들의 묶음” 으로 생각할 수도 있겠습니다.
Implementation
이전의 구현들은 numpy의 퍼포먼스를 끌어올리기 위해서 최대한 vectorized 연산을 활용하였습니다. TIB의 경우, bar를 나누는 기준이 되는 $E_0[\theta_T]$의 값이 bar를 추출하는 과정 중에 지속적으로 업데이트 됩니다. Iterative한 알고리즘으로 구현을 해야 할 것으로 보입니다.
아래의 코드는, 데이터 iterate를 하는 동안 연산의 횟수를 줄이는 데 초점을 맞춘 구현입니다. pandas DataFrame의 loc, iloc은 역할이 다양하여 약간의 overhead가 있습니다. (Pandas doc) 따라서, dataframe 외부에서 tick numbering을 해준 뒤, 한번에 column을 새로 만들어주는 방법을 사용했습니다.
Tick bars의 문제점을 해결하기 위하여 volume bar와 dollar bar로 개념을 확장한 것과 같이, tick imbalance bar의 개념을 volume imbalance bar와 dollar imbalance bar로 확장할 수 있습니다. 거래량 혹은 거래대금의 비대칭이 예상 수준을 넘어설 때 bar를 추출하는 방법입니다. 그 과정은 TIB와 동일합니다.
참고한 서적에서는 $b_t=1$인 경우와 $b_t=-1$인 경우를 따로 구분하여 계산하지만, 저는 약간 다른 방식으로 내용을 이해했습니다. 가장 먼저, 앞서서 정의했던 signed tick을 활용하여 signed volume 혹은 signed value ($c_t$) 를 정의합니다. 여기서 $v_t$는 추출하려는 bar의 종류에 따라 거래량(VIB) 혹은 거래대금(DIB) 값을 사용합니다.
\begin{align*}
c_t = b_t v_t
\end{align*}
다음으로, $T$ 시점에서의 imbalance, $\theta_T$를 아래와 같이 정의합니다.
앞서 살펴본 tick imbalance bar는 signed tick의 누적값을 기준으로 bar를 추출합니다. Tick runs bar는 signed tick을 하나의 값으로 누적하는 것에서 더 나아가, $b_t=1$인 경우와 $b_t=-1$인 경우를 따로 누적하여, 두 수치 사이의 비대칭을 기준으로 bar를 추출하는 방법입니다. 하나의 큰 거래가 호가를 밀면서 체결되거나 여러개의 작은 거래로 나뉘어져서 체결되는 경우 $b_{t=1,…,T}$에 run(연속된 데이터 흔적)을 남기게 되는데, 이를 포착하는 방법입니다.
통계학에서 말하는 run은 동일한 관측값이 (끊김없이) 연속적으로 이어진 것을 의미합니다. (Wikipedia) 이와는 약간 다르게, 서적에서 정의한 run은 데이터의 끊김(sequence break)을 허용합니다. 즉, 여기서 말하는 “run의 길이”는 연속된 데이터의 실질적인 길이를 의미하는 것이 아니라, 일정 기간 동안 관찰된 최빈값의 빈도수를 의미합니다.
다음으로, 현 시점에서 예상되는 다음 run의 길이, $E[\theta_T]$를 구해줍니다.
Tick runs bars의 개념을 확장하여, 거래량 혹은 거래대금으로 runs bars를 추출하는 방법입니다. 먼저, 거래량/거래대금 run($\theta_T$)를 다음과 같이 정의합니다. 위와 마찬가지로, $v_t$는 추출하려는 bar의 종류에 따라 거래량(VRB) 혹은 거래대금(DRB) 값을 사용합니다.
1분봉 데이터를 60분봉 데이터로 변환하려면, 다음과 같이 resampling을 해주면 됩니다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
>>> timebar_1min.resample('60min').agg({ # 기존의 데이터를 60분 단위로 모아서, ... 'open': 'first', # 그룹 중 가장 첫 번째 open 값을 해당 그룹의 open 값으로 사용 ... 'high': 'max', # 그룹 중 가장 큰 high 값을 해당 그룹의 high 값으로 사용 ... 'low': 'min', # 그룹 중 가장 작은 low 값을 해당 그룹의 low 값으로 사용 ... 'close': 'last', # 그룹 중 가장 마지막 close 값을 해당 그룹의 close 값으로 사용 ... 'volume': 'sum', # 그룹 내 volume 값을 모두 더한 값을 해당 그룹의 volume 값으로 사용 ... 'value': 'sum'# 그룹 내 value 값을 모두 더한 값을 해당 그룹의 value 값으로 사용 ... }) open high ... volume value t ... 2021-02-1100:00:0048384000.048840000.0 ... 1288.2345696.193043e+10 2021-02-11 01:00:0047910000.048266000.0 ... 506.4623912.428122e+10 2021-02-11 02:00:0048104000.048376000.0 ... 223.5991071.075957e+10 ... ... ... ... ... 2021-02-15 06:00:0052422000.052670000.0 ... 117.8808506.193310e+09 2021-02-15 07:00:0052653000.052975000.0 ... 223.6723171.180129e+10 2021-02-15 08:00:0052823000.052847000.0 ... 187.0669449.853452e+09 [105 rows x 6 columns]